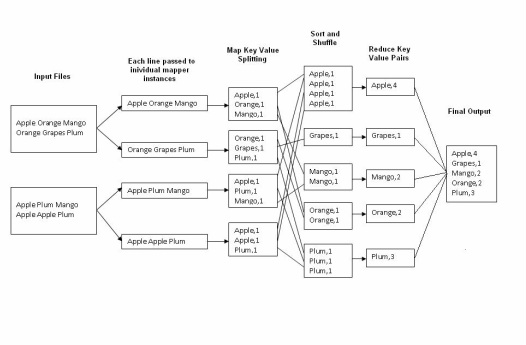
The word count operation takes place in two stages a mapper phase and a reducer phase. In mapper phase first the sentence is tokenized into words then we form a key value pair with these words where the key being the word itself and value ‘1’.
For example
“tring tring the phone rings”
In map phase the sentence would be split as words and form the initial key value pair as
<tring,1>
<tring,1>
<the,1>
<phone,1>
<rings,1>
In the reduce phase the keys are grouped together and the values for similar keys are added. So here there are only one pair of similar keys ‘tring’ the values for these keys would be added so the out put key value pairs would be
<tring,2>
<the,1>
<phone,1>
<rings,1>
This would give the number of occurrence of each word in the input. Thus reduce forms an aggregation phase for keys.
The point to be noted here is that first the mapper class executes completely on the entire data set splitting the words and forming the initial key value pairs. Only after this entire process is completed the reducer starts. Say if we have a total of 10 lines in our input files combined together, first the 10 lines are tokenized and key value pairs are formed in parallel, only after this the aggregation/ reducer would start its operation.
For example
“tring tring the phone rings”
In map phase the sentence would be split as words and form the initial key value pair as
<tring,1>
<tring,1>
<the,1>
<phone,1>
<rings,1>
In the reduce phase the keys are grouped together and the values for similar keys are added. So here there are only one pair of similar keys ‘tring’ the values for these keys would be added so the out put key value pairs would be
<tring,2>
<the,1>
<phone,1>
<rings,1>
This would give the number of occurrence of each word in the input. Thus reduce forms an aggregation phase for keys.
The point to be noted here is that first the mapper class executes completely on the entire data set splitting the words and forming the initial key value pairs. Only after this entire process is completed the reducer starts. Say if we have a total of 10 lines in our input files combined together, first the 10 lines are tokenized and key value pairs are formed in parallel, only after this the aggregation/ reducer would start its operation.
 RSS Feed
RSS Feed
