|
Apache Hadoop has two pillar
1.YARN - Yet Another Resource Negotiator (assigns CPU, memory, and storage to applications running on a hadoop cluster. The first generation of Hadoop could only run MapReduce applications. YARN enables other application frameworks (like Spark) to run on Hadoop as well which opens up lots & lots of possibilities. 2. HDFS - Hadoop Distributed File System (HDFS) is a file system that spans all the nodes in a Hadoop cluster for data storage. It links together the file systems on many local nodes to make them into one big file system. 3. Map Reduce - It is a programming model used for large scale data processing in Hadoop. For more information on Map Reduce follow this link. 4. Hadoop Common – contains libraries and utilities needed by other Hadoop modules. In the American crime drama series Person of Interest, a machine predicts whether a person can be a victim or a perpetrator of a crime. Then it's up to a data scientist to find that person and prevent any violent acts. This may sound like science fiction but Thiruvananthapuram -based big data startup Senzit is trying to turn this into reality. Its digital recording solution captures and archives live events from crime scenes. It then mines hidden insights, patterns and unknown correlations from the vast amount of data that can be collated this way.
International Business Machines, the world's biggest computer-services provider, is taking a keen interest. Senzit is one among at least 100 startups in India that IBM is partnering as it looks to tap cutting-edge innovations in areas such as big data analytics and Internet of Things—devices communicating with each other intelligently. Big Blue's Innovation Centre in Bangalore is partnering with 100 big data and Internet of Things startups across India. Experts said IBM started engaging with these startups five months back as these technologies are strategic for clients such as retailers Walmart, Tesco and banking and financial services firms Barclays and RBS. IBM is also working with Mumbai based startup Algo Engines, which is combining big data analytics and Internet of Things to improve efficiency in wind turbines and solar plants. Courtesy:The Economic Times Quantum computing may be the future of most high-end data centers. This is because as the demand to intelligently process a growing volume of online data grows so the limits of silicon chip microprocessors are increasingly going to be reached. Sooner it will also become impossible to miniaturize traditional computing components further and hence to continue to achieve increase in computer power. Intel's latest microprocessors are based on an industrial process that can produce transistors only 22 nanometers wide. Further advancements in this technology are still possible but at some point miniaturization will come to its physical limit as transistors only a few atoms in size will not be able to function.
One of the major application area for quantum computing will be in the processing of Big Data. As the volume of digital data produced on this Planet continues to grow exponentially therefore a significant potential exists to generate business and social value interlink age with various technologies like Hadoop are currently permitting advancements in the processing of vast data sets. It may well be the development of quantum computers that really pushes large-scale Big Data analysis into the mainstream. Spark is new technology that is on the top of Hadoop Distributed File System (HDFS) that is characterized as “a fast and general engine for large-scale data processing.” Spark have few key features that make it the most interesting upcoming technology in big data world after Apache Hadoop in 2005.
Advantages of Spark are as follows: Speed : It run programs up to 100x faster than Hadoop MapReduce in memory or 10x faster on disk.Also Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing. Ease of Use : It write applications quickly in Java, Scala or Python.Spark offers over 80 high-level operators that make it easy to build parallel apps and can used interactively from the Scala and Python shells. Generality : Combine SQL, streaming, and complex analytics.Spark powers a stack of high-level tools including Shark for SQL, MLlib for machine learning, GraphX, and Spark Streaming. Also these frameworks seamlessly combine in the same application. Integrated with Hadoop : Spark can run on Hadoop 2's YARN cluster manager and can read any existing Hadoop data.If there is a Hadoop 2 cluster then it can run Spark without any further installation .Spark is easy to run standalone or on EC2 or Mesos. It can read from HDFS, HBase, Cassandra, and any Hadoop data source. There are two new technological advancements in Big Data as mentioned below:
The challenges in Big Data are the implementation hurdles which require immediate attention. If these challenges are not handled they may lead to technology failure and also some unpleasant results.
Privacy and Security It is the most important challenges with Big data which is very sensitive & have legal significance. The personal information (e.g. in database of a person on social networking website) of a person when combined with external large data sets leads to the inference of new facts about that person and it’s possible that these facts about that person are infringement in his privacy and the person might not want the data owner to know about them. Also sometimes information regarding the people are collected and used in order to add value to the business of the organization. This is done by creating insights in their lives which they are unaware of. Human Resources and Manpower Since Big data is at its youth and an emerging technology so it needs to attract organizations and youth with diverse new skill. These skills should not be limited to technical but also should extend to research, analytical, interpretive and creative ones. Universities need to introduce curriculum on Big data to produce skilled employees in this field. Technical Challenges With the incoming of new technologies like Cloud computing and Big data it is always important that whenever the failure occurs the damage done should be within acceptable limit rather than beginning the whole task from the beginning. 1.Fault Tolerance Fault-tolerant computing is extremely hard involving complicated algorithms. It is not simply possible to construct 100% reliable fault tolerant machines or software. Thus the main task is to reduce the probability of failure to an acceptable level. Two methods which seem to increase the fault tolerance in Big Data are as: • First is to divide the whole computation being done into tasks and assign these tasks to different nodes for computation. • Second is one node is assigned the work of observing that these nodes are working properly and if something happens that particular task is restarted. But sometimes it’s possible that that the whole computation can’t be divided into independent tasks. There could be tasks which may be recursive in nature and the output of the previous computation of task is the input to the next computation. Thus restarting the whole computation becomes tough process. This can be avoided by applying Checkpoints which keeps the state of the system at certain intervals of the time. In case of any failure, the computation can restart from last checkpoint maintained and helping to retrieve the data . 2.Scalability The scalability issue of Big data has lead towards cloud computing which now aggregates multiple disparate workloads with varying performance goals into very large clusters. This requires a high level of sharing of resources which is expensive and also brings with it various challenges like how to run and execute various jobs so that we can meet the goal of each workload cost effectively. It also requires dealing with the system failures in an efficient manner which occurs more frequently if operating on large clusters. These factors combined put the concern on how to express the programs, even complex machine learning tasks. There has been a huge shift in the technologies being used. Hard Disk Drives (HDD) are being replaced by the solid state Drives and Phase Change technology which are not having the same performance between sequential and random data transfer. Thus, what kinds of storage devices are to be used; is again a big question for data storage. 3.Quality of Data Collection of huge amount of data and its storage comes at a cost. More data if used for decision making or for predictive analysis in business will definitely lead to better results. Business Leaders will always want more and more data storage whereas the IT Leaders will take all technical aspects in mind before storing all the data. Big data basically focuses on quality data storage rather than having very large irrelevant data so that better results and conclusions can be drawn. This further leads to various questions like how it can be ensured that which data is relevant, how much data would be enough for decision making and whether the stored data is accurate or not to draw conclusions from it. United Parcel Service Inc.(UPS) the world’s biggest package shipping company is using Big Data from customers, drivers and vehicles in a new route guidance system that will save time and money and reduce fuel burn.
The On-Road Integrated Optimization and Navigation (Orion) system is being introduced this year to 10,000 of the Atlanta-based company’s 55,000 U.S. drivers. According to UPS Orion has been in development nearly 10 years and is the company’s biggest technological advancement in this time frame. UPS has a history of monitoring and standardizing even the smallest issues, from drivers keeping keys hooked on a finger instead of in their pockets and making only right turns, to increase efficiency and reduce costs. The company declined to provide total savings from technology it has designed and other programs. The latest effort gathers electronic information from UPS customers, from its fleet of 101,000 delivery vehicles and from handheld devices carried by drivers to craft optimal routes that reduce distance, time and fuel. Complicating the task are parcels with specific pickup or delivery times, and the company’s My Choice option that lets customers use a smart phone app to move or delay deliveries. By the end of this year it will have saved UPS more than 1.5 million gallons of fuel and reduced carbon dioxide emissions by 14,000 metric tons, the company said. Using a proprietary system of telematics to gather 200 data points from equipment on each vehicle, UPS in 2012 was able to eliminate 206 million minutes of idling time and save more than 1.5 million gallons of fuel. As part of an effort begun in 2004, delivery routes were designed to minimize left turns, which require vehicles to wait at intersections for oncoming traffic to clear before proceeding. Orion don’t have updates of real-time data that would help drivers avoid accidents and road construction this ability already is being worked on for the next generation of the system. The word count operation takes place in two stages a mapper phase and a reducer phase. In mapper phase first the sentence is tokenized into words then we form a key value pair with these words where the key being the word itself and value ‘1’. For example “tring tring the phone rings” In map phase the sentence would be split as words and form the initial key value pair as <tring,1> <tring,1> <the,1> <phone,1> <rings,1> In the reduce phase the keys are grouped together and the values for similar keys are added. So here there are only one pair of similar keys ‘tring’ the values for these keys would be added so the out put key value pairs would be <tring,2> <the,1> <phone,1> <rings,1> This would give the number of occurrence of each word in the input. Thus reduce forms an aggregation phase for keys. The point to be noted here is that first the mapper class executes completely on the entire data set splitting the words and forming the initial key value pairs. Only after this entire process is completed the reducer starts. Say if we have a total of 10 lines in our input files combined together, first the 10 lines are tokenized and key value pairs are formed in parallel, only after this the aggregation/ reducer would start its operation. 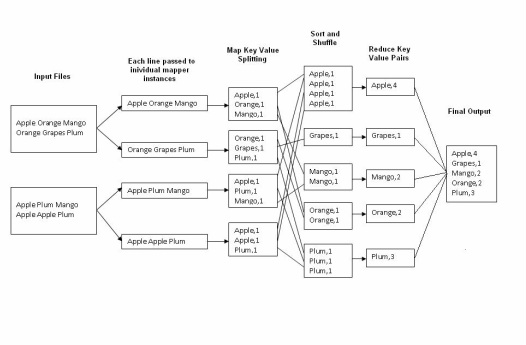 MapReduce is a software framework that allows developers to write programs to process massive amounts of unstructured data in parallel across a distributed cluster of processors or stand-alone computers. It was developed at Google for indexing Web pages in 2004.
The framework is divided into two parts: Map – A function that parcels out work to different nodes in the distributed cluster. Reduce – This function collates the work and resolves the results into a single value. The MapReduce framework is fault-tolerant because each node in the cluster is expected to report back periodically with completed work and status updates. If a node remains silent for longer than the expected interval then the master node makes note and re-assigns the work to other nodes. The key to how MapReduce works is to take input as a list of records. These records are split among the different computers in the cluster by Map. The result of the Map computation is a list of value pairs. Reduce then takes each set of values that has the same key and combines them into a single value i.e. Map takes a set ofdata chunks and produces key pairs and Reduce merges things so that instead of a set of key pair sets we get one result. MapReduce is intended to provide a lightweight way of programming things so that they can run fast by running in parallel on a lot of machines. A Hadoop cluster is a special type of computational cluster designed specifically for storing and analyzing huge amounts of unstructured data in a distributed computing environment.
These clusters run Hadoop's distributed processing software on low-cost commodity computers. Typically one machine in the cluster is designated to work as the NameNode and another machine the as JobTracker which are known as the masters and rest of the machines in the cluster act as both DataNode and TaskTracker which are called slaves. Hadoop clusters are referred as shared nothing systems because the only thing that is shared between nodes is the network that connects them. Hadoop clusters boost the speed of data analysis applications. They also are highly scalable because as volume of data increases nodes could be included in a cluster. Hadoop clusters also are highly resistant to failure because each piece of data is copied onto other cluster nodes which ensures that the data is not lost if one node fails. Facebook is having the largest Hadoop cluster in the world. The Hadoop Distributed File System (HDFS) is the primary storage system used by Hadoop.
HDFS provides high-performance access to data across Hadoop clusters. HDFS has become a key tool for managing pools of big data and supporting big data analytics applications. HDFS is mostly deployed on low-cost commodity hardware therefore server failures are common. Therefore this system is designed to be highly fault-tolerant by facilitating the rapid transfer of data between compute nodes and enabling Hadoop systems to continue running if a node fails. That decreases the risk of catastrophic failure even when numerous nodes fail. HDFS takes in data, it breaks the information down into separate pieces and distributes them to different nodes in a cluster allowing for parallel processing. The file system copies each piece of data multiple times and distributes the copy to individual nodes, placing at least one copy on a different server rack as a result the data on nodes that crash can be found within a cluster which allows processing to continue without any halt. Apache Hadoop is an open source framework for writing and running distributed application that process large amounts of data.
Their are some key distinction of Hadoop which give it an edge over others.
Hadooop's accessibility and simplicity give it an edge over writing and running large distributed programs and on other hand its robustness and scalability make it suitable for even the most demanding jobs at Yahoo and Facebook. Hadoop is divided into two main parts
NoSQL(also known as "Not Only SQL") represents a completely different framework of databases that allows high-performance, agile processing of information at massive scale i.e. it is a database infrastructure that has been very well-adapted to the heavy demands of big data.
The efficiency of NoSQL can be achieved because unlike relational databases that are highly structured, NoSQL databases are unstructured in nature which accounts for its speed & agility. NoSQL revolves around the concept of distributed databases where unstructured data may be stored across multiple processing nodes and often across multiple servers, this distributed architecture allows NoSQL databases to be horizontally scalable as data continues to explode by just adding more hardware without slowing down its performance. The NoSQL distributed database infrastructure has been the solution to handle some of the biggest data warehouses in the world like Google, Amazon, and the CIA. Traditional RDBMS (relational database management system) have been the conventional standard for database management throughout the age of the internet. This is also known as Traditional row-column databases used for both transactional systems, reporting, and archiving. The architecture behind RDBMS is such that data is organized in a highly-structured manner, following the relational model. RDBMS is now considered as a declining database technology. While the organization of the data keeps the warehouse very "neat", the need for the data to be well-structured actually becomes a substantial burden at extremely large volumes which results in performance declines as size gets bigger. Thus RDBMS is generally not considered as a solution to meet the needs of big data.
Examples: Sql Server, MySql, Oracle, etc Big data analytics refers to the process of collecting, organizing and analyzing large sets of data ("big data") to discover patterns and other useful information. Big data analytics help in understanding of the information contained within the data and it also help in identifying the data that is most important for making future business decisions of a company.
Their are several methods for Big Data analysis but the main three techniques are a)RDBMS(Relational Database Management) b)No SQL Database System c)Hadoop & Map Reduce Volume – The quantity of data that is generated is very important it is the size of the data which determines the value and potential of the data under consideration and whether it can actually be considered as Big Data or not. The name ‘Big Data’ itself contains a term which is related to size and hence the characteristic.
Variety- The next aspect of Big Data is its variety. This means that the category to which Big Data belongs to is also a very essential fact that needs to be known by the data analysts. This helps the people, who are closely analyzing the data and are associated with it, to effectively use the data to their advantage and thus upholding the importance of the Big Data. Velocity- The term ‘velocity’ in this context refers to the speed of generation of data or how fast the data is generated and processed to meet the demands and the challenges which lie ahead in the path of growth and development. Variability- This is a factor which can be a problem for those who are analyse the data. This refers to the inconsistency which can be shown by the data at times, thus hampering the process of being able to handle and manage the data effectively.  Medical Records The extreme cost of healthcare in the U.S. can be reduced with the adoption of electronic patient medical records. Many companies are searching way out to explore through large volumes of clinical data on medication, allergies and procedure data that is often saved by different practitioners in different formats. Apixio, a company based in San Mateo, California, makes a platform that streamlines patient records across disparate types of data to offer a search able database for providers.  Telecom Data Phone calls, texts, apps, the surge of data generated by mobile devices had created data management problems for service providers. These service providers rely largely on the analysis of this data to provide better customer service and to build on retention and loyalty. To manage this large Big Data a company Infobright, based in Toronto came in action which compresses mobile data for telecom companies at a 10:1 ratio resulting in less storage space and faster, real-time analytics.  Retail Transactions Most retailers already store point-of-sale data from customer transactions but McKinsey & Company, a management-consulting firm, estimates that a retailer using big data analytics to its fullest potential could increase its operating margin by more than 60 percent. A California based Nearbuy Systems offers an in-store guest WiFi platform that allows retailers to view which websites shoppers view before making a purchase then analyze that data across multiple store locations.  Social Media Activity Big companies are desperate to capture millions of tweets, Facebook posts, YouTube videos, and Tumblr pages that mention their product or service. Gnip, a company based in Colorado has found a niche market. Gnip collects and manages public high-volume streams from multiple social media platforms, including Facebook, Twitter, Tumblr, Wordpress, and StumbleUpon. The company also offers its customers a searchable 30-day full historical database of Twitter.  Financial Data
Banks and investment firms assess massive amounts of data to stay ahead of the competition. In 2011 trading volume grew to 4.55 billion which is up by 17 percent from 2010. The American Banker's Association reports that there are 10,000 credit card transactions every second around the world. Datameer a company based in San Mateo, Calif provides an analytics platform that helps banks mine large volumes of customer data, such as spending behavior and other demographics, to improve their products and marketing campaigns. 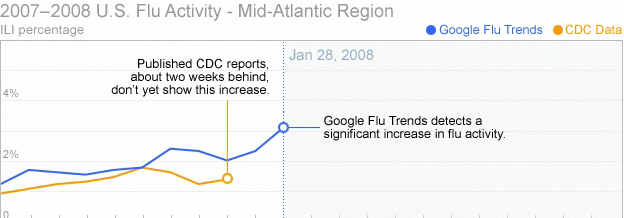 In 2009 a new virus was discovered ,combining elements of bird flu & Seasonal flu the virus strain dubbed H1N1 and spread quickly similar to Spanish flu in 1918 that infected half billion and killed ten million. The worst part was that their was no vaccine & the authorities could only reduce its spreading speed.
United States Centers for Disease Control and Prevention (CDC) requested doctors to inform them about the new flu but the picture of pandemic that emerged was always a week or two out of date which completely blinded the public health agencies at the most crucial time. At that time engineers at the internet giant Google published a remarkable paper in a scientific journal Nature which created a splash among health official & computer scientist. Since Google receives more than three billion queries everyday and saves all of them so that they have plenty of data to work with. Google took 50 million most common search terms that Americans type and compared the list CDC data. The idea was to identify areas infected by the flu virus by what people searched for on the internet but no one else other than Google had so much data processing power. What their system did was to look for correlations beteween the frequency of certain search quereies and the spread of the flu over time and space. They almost processed 450 million different mathematical models in order to test the search terms and compared it to actual CDC anlysis. Finally they found a combination of 45 search terms that when used together in a mathematical model had a strong correlation between their prediction and the official figures but unlike CDC they could tell it in real time and not a week or two. Big data is defined as data that is too big, fast & hard for existing tools to process. Here, “too big” means that now a days organizations have to deal with petabyte scale collections of data which either come from click streams, transaction records, sensors and many more . “Too fast” means that data is not only big but it needs to be processed quickly. For example, to perform fraud detection at a point of sale, or determine what ad to show to a user on a web page. “Too hard” for data means that it doesn’t fit neatly into an existing processing tool i.e. data needs more complex analysis tools than the present existing ones. Big Data means massive volumes of information, IBM reports that over 2.7 zetabytes of data exist in the digital universe today with over 571 new websites being created per minute per day. Google is a source of ‘big data’ In 2008, Google already processed 20,000 terabytes of data (20 petabytes) a day. 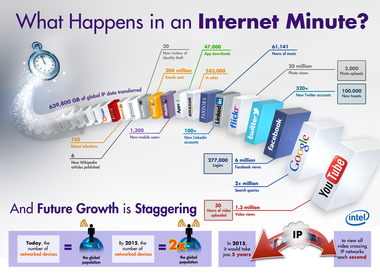 |
AuthorI am a student pursuing Bachelors of computer science and love to explore new things. Technology is my life & completely rely on it. Our Motto:
“Being the richest man in the cemetery doesn't matter to me. Going to bed at night saying we've done something wonderful... that's what matters to me.” ― Steve Jobs Archives
December 2014
Categories
All
|
 RSS Feed
RSS Feed
